| Vision Module Guide |
|
||
| chil home > projects > ACT-R/PM > documentation > | |||
A guide to understanding and using ACT-R/PM's Vision Module.
The Vision Module is the most complicated of the RPM Modules. As one might expect, the Vision Module is used to determine what ACT-R "sees." The Vision Module has two subsystems, the dorsal "where" system and the ventral "what" system. This Guide will explain the two subsystems and how to use them, and then describe in a little more detail how the Vision Module is actually implemented.
When a production makes a request of the “where” system, the production specifies a series of constraints, and the “where” system returns a chunk representing a location meeting those constraints. Constraints are attribute-value pairs which can restrict the search based on visual properties of the object (such as “color: red”) or the spatial location of the object (such as “screen-y greater-than 153”). This is akin to so-called “pre-attentive” visual processing (Triesman & Gelade, 1980) and supports visual pop-out effects. For example, if the display consists of one green object in a field of blue objects, the time to determine the location of the green object is constant regardless of the number of blue objects.
The constraints are specified with a +visual-location> buffer
request. For more information about the form of that, see the Command
Reference. If there is an object on the display that meets those constraints,
then a chunk representing the location of that object is placed in the visual-location
buffer. If multiple objects meet the constraints, then the newest one--that is,
the one with the most recent onset--will be used. If multiple objects meet the
constraints and they have the same onset, then one will be picked randomly. If
there are no objects which meet the constraints, then the error chunk
will be placed in the buffer.
Onsets play one other role in the system. If the visual-location buffer is empty (it can be emptied manually with the -visual-location> RHS command) and something new appears, its location will be placed automatically (the informal term is "stuffed") into the visual-location buffer.
A request to the “what” system entails providing a chunk representing
a visual location, which will cause the “what” system to shift visual
attention to that location, process the object located there, and place a chunk
representing the object into the =visual> buffer. This is accomplished
with the +visual> command; Command
Reference for details. The amount of time this takes is controlled by the
:VISUAL-ATTENTION-LATENCY parameter, which has a default of 85 ms.
If there is more than one object at the location specified when the attention shift completes, only one of them gets encoded and placed in the =visual> buffer. The Vision Module arbitrates among the objects by using the constraints last passed to the “where” system for that visual location. Thus, if the location passed in was constrained to be red, and there are three objects at the location, one of which is red, then the red one will be encoded.
The Vision Module also has a rudimentary tolerance for movement. That is, if the location chunk passed in to the what system specifies a location of #(100 125) and the object there moves a little, there will be no error generated if the movement is small. Just how far an object can move and still be encoded is dependent on the value of the :VISUAL-MOVEMENT-TOLERANCE parameter, which defaults to 0.5 degrees of visual angle. That means the object can have moved by up to 0.5 degrees of visual angle and still be processed without requesting a new location from the "where" system.
The basic assumption behind the Vision Module is that the visual-object chunks are episodic representations of the objects in the visual scene. Thus, a visual-object chunk with the value "3" represents a memory of the character "3" available via the eyes, not the semantic THREE used in arithmetic--some retrieval would be necessary to make that mapping. Same thing with words and such. Note also that there is no "top-down" influence on the creation of these chunks; top-down effects are assumed to be a result of ACT's processing of these basic visual chunks, not anything that ACT does to the Vision Module. (See Pylyshyn, 1999 for a clear argument about why it should work this way.)
The Vision Module has a rudimentary ability to track moving objects. The basic
pattern is to attend the object, then issue a +visual> command
to start tracking (again, see the Command Reference).
This will cause the Vision Module to stay BUSY until a -visual>
command is sent or another +visual> command is sent. While tracking,
both the visual object and visual buffer locations will be updated as the object
moves.
There is a more detailed way to compute the latency of attention shifts with an eye-movement model called EMMA (Salvucci, 2001) based on Reichle, Rayner, and Pollatsek's (1999) E-Z Reader. The more detailed model makes the time between the shift request and the generation of the chunk representing the visual object dependent on the eccentricity between the requested location and the current point of gaze, with nearer objects taking less time than further objects. EMMA is considered an "extra" so please see the RPM "extras" folder for more information.
The Vision Module takes a window and parses the objects in that window. Each object will be represented by one or more features in the Vision Module's visicon. These features are the basic units with which ACT-R interacts. Each feature contains information about what kind of screen object it represents, where it is, and so on. This is depicted in Figure 1.
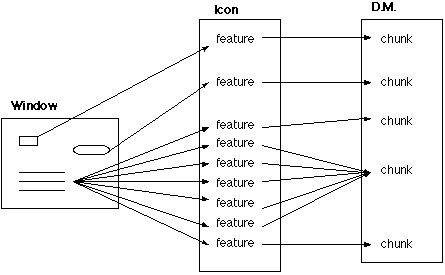
Figure 1. Vision Module configuration.
The mapping from screen objects to icon features is not necessarily one-to-one. A screen object can create multiple features, depending on what that screen object is and how the Vision Module is configured. Most screen objects will generate one feature, the most common exception being anything containing text. (Text is a little more complex and has its own section below.)
The Vision Module creates chunks from these features which provide declarative memory representations of the visual scene, which can then be matched by productions. For the Vision Module to create a chunk for an object, visual attention must first be directed to the location of that object, as described above in the "what" system.
When a location is being attended by the Vision Module, and the visual world changes at that location, the Vision Module will automatically update the contents of the =visual> buffer. The upshot of this is that when the world at a location changes, the Vision Module will register briefly as "busy" while it re-encodes the new object (or lack of one) at that location.
This behavior is sometimes undesireable. For instance, in response to the user clicking the mouse or typing a key, the stimulus disappears. A new one appears somewhere else. Attention cannot be shifted to that new location right away because the visual system is busy processing the current location. This makes response to the new stimulus slow.
The solution to this problem is for a production to tell the Vision Module that the cognitive system is done with the currently-attended object, and thus attention should be un-allocated. This is done by issuing a -visual> on the RHS of a production.
Text will get parsed into multiple features. If :OPTIMIZE-VISUAL is true (the default), then each word in the text will be parsed into one feature. Thus, long sentences will be parsed into many features. If :OPTIMIZE-VISUAL is false, then each letter is parsed into multiple features.
There are several options for what features will result from carving up the letters; there is no universally agreed-upon way to do this. One option (the default) is to carve the letters into features consisting of a LED-type representation of the characters of the text. The following shows a graphical representation of the features, the number values associated with each feature, the letter E made from the features, and an abstract-letter chunk representing the letter E.
- - 1 2 - - |\|/| 34567 | (letter-e - - 8 9 - - isa abstract-letter |/|\| 01234 | value "E" - - 5 6 - - line-pos (1 2 3 8 9 10 15 16))
Different feature sets have been made available, including Gibson's (1968) set and Briggs & Hochevar's (1975) set.
The other complication here is the scale option to a +visual> request. If optimizing is on, then the basic unit is words, though the Vision Module can be told to look for phrases. If optimizing is off, then the Vision Module can be told to look for letters, words, or phrases. Letters are synthesized from clusters of the LED-style features according to a Bayesian categorization algorithm to determine the best letter given a set of LED features.
Simple visual tasks with familiar screen objects like text is fairly straightforward and doesn't require much in the way of Lisp hacking. However, more complex displays often do. Here's a rundown of some of the things you might need to do:
Creating icon features is handled by the device, so please see the section on the Device Interface.
If you define your own class for visual features with your device, you may also want some way of translating those features into chunks. There are at least two approaches to handling this:
[1] Create your subclass with visual-object as the default for the kind slot and whatever you want for the value slot. RPM will use the default feat-to-dmo method on your features to translate them into chunks of type visual-object. This approach is fairly limited but is simple.
[2] Along with your class of features, define a chunk type to represent objects of this feature class and :include the visual object chunk in that definition. Be sure the kind slot in your feature objects matches the name of the chunk type you defined. You will then need to write a feat-to-dmo method for your feature class which translates feature objects into declarative memory objects. (Declarative memory objects--or DMO's--are how RPM understands chunks. Creating DMO's also creates ACT-R chunks.) Probably the best way to do this is use call-next-method to get the default slots (e.g. location, kind) set and then use set-attribute on the result to set the remaining slots. To go back to the arrow example, you'll need a chunk type which encodes an arrow:
(chunk-type (arrow (:include visual-object)) direction)
There needs to be a method for going from a feature to a chunk (this happens when move attention is called on the location at which the feature resides), which is a feat-to-dmo method:
(defmethod feat-to-dmo :around ((self arrow-feature))
(let ((the-chunk (call-next-method)))
(set-attribute the-chunk `(direction ,(direction self)))
the-chunk))
This is a little tricky, since it's an :around method that knows what the default feat-to-dmo method does, which is note that this feature has been attended, generate a DMO representing the object, and return that DMO. The :around method just takes the returned DMO and modifies it. The base method is this:
(defmethod feat-to-dmo ((feat icon-feature))
"Build a DMO for an icon feature"
(setf (attended-p feat) t)
(make-dme (dmo-id feat) (isa feat)
`(screen-pos ,(id (xy-to-dmo (xy-loc feat) t))
value ,(value feat)
color ,(color feat))
:obj (screen-obj feat)
:where :external))
If you don't want to mess with :around methods, you could just write it like this:
(defmethod feat-to-dmo ((feat arrow-feature))
"Build a DMO for an arrow icon feature"
(setf (attended-p feat) t)
(make-dme (dmo-id feat) (kind feat)
`(screen-pos ,(id (xy-to-dmo (xy-loc feat) t))
value ,(value feat)
color ,(color feat)
direction ,(direction feat))
:obj (screen-obj feat)
:where :external))
I don't do it that way just because it's a lot of redundant code, but you can do it however you like.
![]()
| People Facilities Research Projects Miscellany Search | Home |
Last modified 2004.03.02